تضمین لبخندی زیبا
خمیر دندان های دنتامکس
آنتی باکتریال ، ضد لک و تشکیل پلاک ، ضد پوسیدگی ، خوشبوکننده واقعی دهان ، کاهش دهنده التهاب لثه و سفید کننده

آنتی باکتریال با اثر طولانی مدت ، ضد تشکیل پلاک ، خوشبوکننده واقعی دهان ، حاوی ترکیبات طبیعی و ضد پوسیدگی با کمک حداکثر فلوراید

دندان های قوی ، محافظت از مینای دندان ، تسکین بخش حرفه ای ، دارای ماده نانوهیدروکسی آپاتیت و حاوی مواد درجه یک اروپایی

تسکین دهنده موثر دندانهای حساس ، خنک کننده و خوشبوکننده واقعی دهان ، ضد پوسیدگی با کمک حداکثر فلوراید و حاوی مواد درجه یک اروپایی

دندان های قوی ، سلامت دهان ، دارای عصاره طبیعی گیاه سالوادورا پرسیکا ، ضد پوسیدگی با کمک حداکثر فلوراید و ضد تشکیل پلاک
ضد لک و تشکیل پلاک ، ضد حاوی عصاره طبیعی آلوئه ورا ، حاوی ماده طبیعی زانتان ، حاوی ویتامین E و با قابلیت پخش مناسب در دهان مخصوص ارتودونسی
محصولات






گالری عکس





دنتامکس حاوی مواد اولیه اروپایی

سوئیس

فرانسه

آلمان

پرتقال
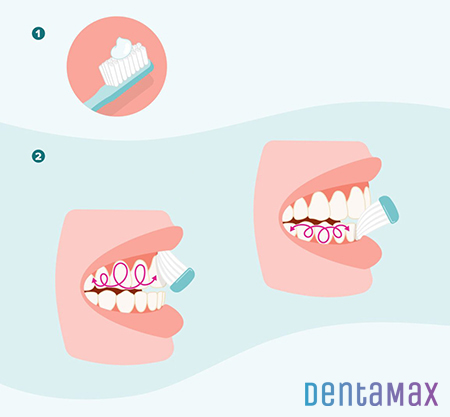
آیا میدانستید … ؟